题目
小申最近在申请一个关于手机APP下载情况的课题,为此他从某移动数据分析平台上下载了2022年1-4月“中国区App热门应用下载榜”的部分数据。经初步整理,得到了名为“热门应用下载榜.csv”的数据文件,部分数据如下。请根据以上情境回答以下问题。 APP名称 应用领域 1月下载量 2月下载量 3月下载量 4月下载量 微信 社交通讯 10515227 10586023 5595338 2612807 QQ 社交通讯 4840495 5549392 3270954 2196967 微博 社交通讯 1488020 1357479 1397596 1278586 拼多多 综合电商 7980282 5189566 6412028 4300543 京东 综合电商 2440802 2866637 2235491 2058659 美团 综合电商 2431001 2572887 1967273 1566847 饿了么 综合电商 1528579 1215251 1451845 1809349 叮咚买菜 综合电商 645569 603302 847805 2085682 得物 综合电商 3316854 1991585 1335633 淘宝 综合电商 4416424 4027143 2978742 1909709 快手 休闲娱乐 7940261 2519546 2744268 2058346 快手极速版 休闲娱乐 4046872 2157658 2633956 4003789 饿了么 综合电商 1528579 1215251 1451845 1809349 抖音 休闲娱乐 8754023 8739191 5335021 3140634 抖音极速版 休闲娱乐 3518013 3197681 2516428 5082916 王者荣耀 休闲娱乐 2838336 2322328 1857879 2314643 拼多多 综合电商 7980282 5189566 6412028 4300543 百度 浏览器 3297148 3368248 2471573 2145527 夸克 浏览器 2787658 1415321 2736426 6370253 爱奇艺 综合视频 2152280 2647844 2504231 2134187 哗哩哗哩 综合视频 1689264 1451845 1941582 (1)小申发现数据表中存在问题数据,他用python对这些数据进行整理,删除其中的重复值和缺失值。以下能实现数据整理要求的是 ____ 。import pandas as pd-|||-#读取csv文件-|||-df=pd.read_csv ("热门应用下载榜.csv", tan Codmg=AMS(I)^n)-|||-#删除重复值,保留第一条记录-|||-=dt.. ① __ (sin angle EBE=(1)^circ APF 名称"], keep="② __ -",inplace=False)-|||-#删除有缺失值的行-|||-=AF. ③ __ (div b=0 ,how=" ④ __ -",inplace=False)-|||-#保存整理后的数据表-|||-df.to_csv("热门应用下载榜整理版.csv", tan COdtan (8)^circ Asin (Br)^circ )A.①dropduplicates;②first;③drop_na;④anyB.①drop_duplicates;②last;③dropna;④allC.①drop_duplicates;②first;③dropna;④anyD.①dropduplicates;②last;③drop_na;④any(2)小申需要统计4月下载量最多的APP,他编写了以下代码,则横线处可以实现上述功能的函数是 ____ 。import pandas as pd-|||-#读取csv文件-|||-df=pd.read_csv ("热门应用下载榜.csv", tan Codmg=AMS(I)^n)-|||-#删除重复值,保留第一条记录-|||-=dt.. ① __ (sin angle EBE=(1)^circ APF 名称"], keep="② __ -",inplace=False)-|||-#删除有缺失值的行-|||-=AF. ③ __ (div b=0 ,how=" ④ __ -",inplace=False)-|||-#保存整理后的数据表-|||-df.to_csv("热门应用下载榜整理版.csv", tan COdtan (8)^circ Asin (Br)^circ )A.minB.maxC.meanD.value_counts(3)为统计3月综合电商应用领域中下载量超过两百万的APP,下列筛选的条件表达式中正确的是 ____ 。A.df[(df[“应用领域”]=“综合电商”)and(df[“3月下载量”]>=2000000)]B.df[(df[“应用领域”]=“综合电商”)or(df[“3月下载量”]>=2000000)]C.df[(df[“应用领域”]==“综合电商”)|(df[“3月下载量”]>=2000000)]D.df[(df[“应用领域”]==“综合电商”)&(df[“3月下载量”]>=2000000)](4)小申统计了下载榜中不同应用领域的APP所占的比例,绘制了如下饼图,请帮助小申完善以下程序,① ____ 【选填:min( )/max( )/sum( )/value_counts( )】,② ____ 。import pandas as pd-|||-#读取csv文件-|||-df=pd.read_csv ("热门应用下载榜.csv", tan Codmg=AMS(I)^n)-|||-#删除重复值,保留第一条记录-|||-=dt.. ① __ (sin angle EBE=(1)^circ APF 名称"], keep="② __ -",inplace=False)-|||-#删除有缺失值的行-|||-=AF. ③ __ (div b=0 ,how=" ④ __ -",inplace=False)-|||-#保存整理后的数据表-|||-df.to_csv("热门应用下载榜整理版.csv", tan COdtan (8)^circ Asin (Br)^circ )
小申最近在申请一个关于手机APP下载情况的课题,为此他从某移动数据分析平台上下载了2022年1-4月“中国区App热门应用下载榜”的部分数据。经初步整理,得到了名为“热门应用下载榜.csv”的数据文件,部分数据如下。请根据以上情境回答以下问题。
(1)小申发现数据表中存在问题数据,他用python对这些数据进行整理,删除其中的重复值和缺失值。以下能实现数据整理要求的是 ____ 。

A.①dropduplicates;②first;③drop_na;④any
B.①drop_duplicates;②last;③dropna;④all
C.①drop_duplicates;②first;③dropna;④any
D.①dropduplicates;②last;③drop_na;④any
(2)小申需要统计4月下载量最多的APP,他编写了以下代码,则横线处可以实现上述功能的函数是 ____ 。

A.min
B.max
C.mean
D.value_counts
(3)为统计3月综合电商应用领域中下载量超过两百万的APP,下列筛选的条件表达式中正确的是 ____ 。
A.df[(df[“应用领域”]=“综合电商”)and(df[“3月下载量”]>=2000000)]
B.df[(df[“应用领域”]=“综合电商”)or(df[“3月下载量”]>=2000000)]
C.df[(df[“应用领域”]==“综合电商”)|(df[“3月下载量”]>=2000000)]
D.df[(df[“应用领域”]==“综合电商”)&(df[“3月下载量”]>=2000000)]
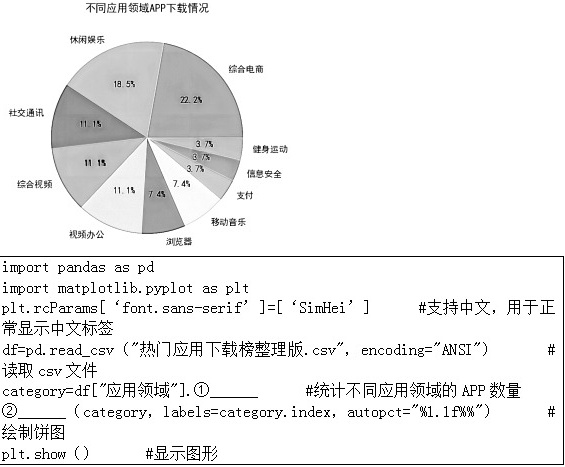
(4)小申统计了下载榜中不同应用领域的APP所占的比例,绘制了如下饼图,请帮助小申完善以下程序,① ____ 【选填:min( )/max( )/sum( )/value_counts( )】,② ____ 。
| APP名称 | 应用领域 | 1月下载量 | 2月下载量 | 3月下载量 | 4月下载量 |
| 微信 | 社交通讯 | 10515227 | 10586023 | 5595338 | 2612807 |
| 社交通讯 | 4840495 | 5549392 | 3270954 | 2196967 | |
| 微博 | 社交通讯 | 1488020 | 1357479 | 1397596 | 1278586 |
| 拼多多 | 综合电商 | 7980282 | 5189566 | 6412028 | 4300543 |
| 京东 | 综合电商 | 2440802 | 2866637 | 2235491 | 2058659 |
| 美团 | 综合电商 | 2431001 | 2572887 | 1967273 | 1566847 |
| 饿了么 | 综合电商 | 1528579 | 1215251 | 1451845 | 1809349 |
| 叮咚买菜 | 综合电商 | 645569 | 603302 | 847805 | 2085682 |
| 得物 | 综合电商 | 3316854 | 1991585 | 1335633 | |
| 淘宝 | 综合电商 | 4416424 | 4027143 | 2978742 | 1909709 |
| 快手 | 休闲娱乐 | 7940261 | 2519546 | 2744268 | 2058346 |
| 快手极速版 | 休闲娱乐 | 4046872 | 2157658 | 2633956 | 4003789 |
| 饿了么 | 综合电商 | 1528579 | 1215251 | 1451845 | 1809349 |
| 抖音 | 休闲娱乐 | 8754023 | 8739191 | 5335021 | 3140634 |
| 抖音极速版 | 休闲娱乐 | 3518013 | 3197681 | 2516428 | 5082916 |
| 王者荣耀 | 休闲娱乐 | 2838336 | 2322328 | 1857879 | 2314643 |
| 拼多多 | 综合电商 | 7980282 | 5189566 | 6412028 | 4300543 |
| 百度 | 浏览器 | 3297148 | 3368248 | 2471573 | 2145527 |
| 夸克 | 浏览器 | 2787658 | 1415321 | 2736426 | 6370253 |
| 爱奇艺 | 综合视频 | 2152280 | 2647844 | 2504231 | 2134187 |
| 哗哩哗哩 | 综合视频 | 1689264 | 1451845 | 1941582 |
A.①dropduplicates;②first;③drop_na;④any
B.①drop_duplicates;②last;③dropna;④all
C.①drop_duplicates;②first;③dropna;④any
D.①dropduplicates;②last;③drop_na;④any
(2)小申需要统计4月下载量最多的APP,他编写了以下代码,则横线处可以实现上述功能的函数是 ____ 。
A.min
B.max
C.mean
D.value_counts
(3)为统计3月综合电商应用领域中下载量超过两百万的APP,下列筛选的条件表达式中正确的是 ____ 。
A.df[(df[“应用领域”]=“综合电商”)and(df[“3月下载量”]>=2000000)]
B.df[(df[“应用领域”]=“综合电商”)or(df[“3月下载量”]>=2000000)]
C.df[(df[“应用领域”]==“综合电商”)|(df[“3月下载量”]>=2000000)]
D.df[(df[“应用领域”]==“综合电商”)&(df[“3月下载量”]>=2000000)]
(4)小申统计了下载榜中不同应用领域的APP所占的比例,绘制了如下饼图,请帮助小申完善以下程序,① ____ 【选填:min( )/max( )/sum( )/value_counts( )】,② ____ 。
题目解答
答案
解:(1)drop_duplicates( )函数是Pandas中最基础的,也是最重要的去重工具,它可以非常快速、有效地删除列表中重复的元素;data.dropna( )#直接删除记录;函数pandas.DataFrame.drop_duplicates(subset=None,keep='first',inplace=False,ignore_index=False)主要用来去除重复项,返回DataFrame类型的数据。所以选项C符合题意;
(2)numpy中的mean( )函数:该函数的功能是统计数组元素的平均值,所以此处需要表示最大值为max函数;
(3)为统计3月综合电商应用领域中下载量超过两百万的APP,筛选的条件表达式为df[(df[“应用领域”]=“综合电商”)and(df[“3月下载量”]>=2000000)];
(4)value_counts( ) 方法返回一个序列Series,该序列包含每个值的数量。也就是说,对于数据框中的任何列,value-counts ( ) 方法会返回该列每个项的计数。python用plt.pie绘制饼图。
故答案为:C B A ①value_counts( ),②plt.pie
(2)numpy中的mean( )函数:该函数的功能是统计数组元素的平均值,所以此处需要表示最大值为max函数;
(3)为统计3月综合电商应用领域中下载量超过两百万的APP,筛选的条件表达式为df[(df[“应用领域”]=“综合电商”)and(df[“3月下载量”]>=2000000)];
(4)value_counts( ) 方法返回一个序列Series,该序列包含每个值的数量。也就是说,对于数据框中的任何列,value-counts ( ) 方法会返回该列每个项的计数。python用plt.pie绘制饼图。
故答案为:C B A ①value_counts( ),②plt.pie